WebRTC has been around for over a decade and promises excellent scalability for most use cases. You’d often have come across Video CPaaS vendors who’re democratising and actively boosting the spread of WebRTC for usage by app developers, so the latter can use it for various use cases without necessarily understanding the core tech in deep detail.
Like many technologies, WebRTC is inherently complex. To make a production grade WebRTC application, one requires a complex intermix of engineering spanning across network engineering, video engineering, VOIP or similar RTC custom protocols, UI/UX etc.
WebRTC’s deep integration with CPaaS vendors brings a win-win model for application developers. This happens through economies of scale, continuous and rapid enhancement of the WebRTC-based video platform, compatibility, and support w.r.t ever changing and rapidly evolving browsers stacks and mobile development frameworks.
EnableX has been at the forefront of offering all these essentials by using a very exhaustive set of DIY Video APIs, while also providing a no-code, yet highly customisable, off the shelf UI-based video platform.
While building this we set off on a journey to offer a speech to text functionality for our WebRTC based CPaaS platform – EnableX. This is one of the most requested features by our customers as it opens new possibilities of running post session AI analysis.
As usual as it may seem, you would have experienced this in different forms on some of the existing enterprise video communication applications such as Microsoft teams or Zoom. However, working with EnableX, you can fetch converted speech to text in real-time and embed it within your business application.
For example, imagine there’s an app that evaluates the speech to text response that can now further assess grammar construction, speech style, word complexity, vocabulary, etc. Using NLP engines.
Another possibility- a video session with a large group where participants join from across the world and do not share a common language. The availability of a real-time speech conversion in their respective spoken language can help overcome the language barrier.
So, how do you create a WebRTC based speech to text system?
Your first attempt can be to use the Web Audio to capture the respective browser audio from every end point participating in the video session and then, send it to a cloud based speech to text service.
Significant problems in the above approach:
- Doubles the end point bandwidth – Audio data is sent both to the cloud-based speech to text service and duplicated audio packets are also sent into the video session.
- Non-scalable – The cost impact will be high for a large group (say 100+) where everyone is sending their audio to the speech to text platform and the converted speech is shared with everyone else. Not to mention, it can also choke client upload/downlink bandwidth (because of receiving speech to text data from 100+ people continuously), so it is not a technically feasible solution.
- Device support – For mobile apps built on top of native app or hybrid framework, you have to further explore on how to replicate the speech to text functionality and develop independent solutions.
The next attempt is to move it to the server side. Let the server do the heavy lifting of constantly translating the speech to text. Of course there are many challenges you will have to overcome if you decide to do it on the server side – WebRTC audio is transported on SRTP streams, OPUS based encoding, ease of access of cloud-based service and its interoperability with server stack, horizontal scalability, and vertical scalability.
But beating the scalability problem is still difficult. Let us understand it in more detail.
Average human spoken word rate is 150 wpm. If there are 50 people whose mic activity is captured and constantly translated, it means a 150 * 50 = 7500 wpm . Every word is around an average of 6 characters. which in this case, totals to 45000 characters per minute. However, the speech to text conversion gets continuously refined during the conversion process so the actual data rate is much higher.
A practical way to solve it is to only convert the speech to text for the top “N” active talkers and share the converted speech with each user. The Active talker functionality in an interactive video based platforms allows you to choose and send the top most recent talkers.
https://www.enablex.io/insights/active-talker-giving-an-edge-to-your-video-conference/
Given the unique capabilities of EnableX, such as server-side active talker, horizontally scalable video platform, and its interoperable capabilities for Voice and Voice API working side by side using highly scalable EnableX Gateway, we’ve built a highly scalable on demand speech to text capability which can be initiated with a single API call.
Here’s how it’ll come alive-
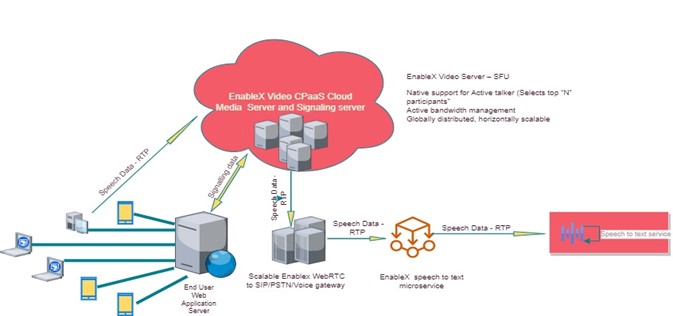
Using EnableX’s text to speech feature, you get the follow key advantages
- Horizontally scalable – You can run any number of concurrent rooms and they all can be transcribed.
- Always ON or can be enabled on demand – Rooms can be configured to be always transcribed or transcription can be enabled by room participants on-demand
- Speaker identification
- Support for 100+ languages
- Using EnableX data store feature, transcription for the room can be either saved to be fetched later or can be stored at customer’s end
- Speech to text converter joins as a silent participant into the room – This can be useful for audit purpose
To get access to EnableX Speech to text API, please refer to the link below:
Web – JavaScript SDK
Live Transcription: Web SDK – Video API – EnableX Developer Centre
Android –
Live Transcription: iOS SDK – Video API – EnableX Developer Centre (vcloudx.com)
IOS –
Live Transcription: iOS SDK – Video API – EnableX Developer Centre (vcloudx.com)